마크베이스(Machbase)를 이용한 반도체 생산 데이터 관리 및 검색 방법
- 2024년 4월 11일
- 3분 분량
최종 수정일: 2024년 7월 19일
반도체 생산 데이터는 생산 장비에 설치된 대량의 센서들에서 발생하는 센서 데이터와 생산된 제품에 대한 정보가 혼합되어 있습니다. 이 데이터는 매우 방대하며, 센서 데이터의 수집 주기에 따라 반도체 웨이퍼 하나에 대한 생산 정보가 수 GB에 달하는 경우도 발생합니다.

반도체 생산 데이터는 위와 같은 형태로 기록되고 있는데요. 이를 xml 파일로 만들어서 hadoop 등의 no-sql 빅데이터 처리 시스템에 저장하여 분석하거나, 위 데이터를 xml 형태의 BLOB 칼럼에 RDBMS에 저장하는 형태로 처리하고 있었습니다.
실제 각 센서의 데이터는 wafer xml 파일에 포함되어 있어서 시간별 센서 값의 추이를 살펴보기에는 적합한 형태는 아닙니다.
데이터 처리의 문제
생산품 기준의 센서 데이터 기록 방식(서론에서 기술한)은 실제 상황에서 다양한 문제가 발생하였습니다. 이들 문제는 대량의 센서 데이터 처리에 있어서 일반적으로 많이 발생하는 문제이지만, 여기에서도 다시 한번 살펴보겠습니다.
Hadoop을 이용할 경우, 대량/고속의 데이터가 발생하여도 입력 문제는 없으나, 원하는 통계 분석 등을 위해서 센서 데이터를 읽어 들일 때 지나치게 오랜 시간이 걸려서 실시간 분석 등은 불가능하다. Spark 등을 도입하면 검색 성능을 좀 더 향상시킬 수 있으나 대규모 cluster를 구축하여야 하므로 HW에 투자하는 비용이 과하다.
RDBMS는 입력 성능이 저조하여 원하는 양의 데이터 입력에 문제가 있으며, 일부 Appliance를 이용하면 일정 수준까지는 입력 성능을 향상시켜 사용이 가능하지만 막대한 비용이 투자되어야 하며, 여전히 입력 성능이 만족스럽지 않다.
이러한 문제들을 해결하기 위해서, 시계열 센서 데이터 전문 DBMS인 마크베이스를 이용하여 최근에 데이터 처리를 수행하려고 테스트를 진행하고 있습니다. 이 포스트에서 마크베이스의 DB 구성을 어떻게 설정해야 고속 데이터 입력 및 고객이 원하는 데이터 검색을 할 수 있는지를 살펴봅니다.
검색 대상 데이터 정의
마크베이스 Tag 테이블은 시간별로 각 센서의 값을 저장하고, 센서 tag 식별자와 시간 범위를 조건으로 검색하면, 수조개의 센서 데이터에 대해서도 매우 빠른 속도로 검색이 가능한 특징이 있습니다. 하지만, 이 Tag 테이블은 생산정보(각 센서가 그 시점에 어느 wafer를 생산하고 있었는지, 그때 사용된 레시피가 무엇이었는지)를 저장하고, 이를 조건으로 검색하는 경우에는 성능적인 한계가 있습니다. 고객이 원하는 검색 화면의 예는 아래와 같습니다.

이 그림에서, 고객은 어느 특정 센서 tag, 시간 범위를 지정하지 않고, 센서들을 장착하고 있는 장비의 모듈을 선택하고, 특정한 시간을 지정하기보다는 생산된 웨이퍼의 Lot 번호 혹은 웨이퍼 번호를 선택하여, 각 센서의 데이터를 시각화하거나 통계 값을 표시하는 것을 원합니다. 이와 같은 데이터 조회를 빠르게 수행하기 위해서 반도체 생산 wafer 데이터를 좀 더 가공하여 입력할 필요가 있습니다.
마크베이스 TAG 테이블을 위한 데이터 전처리
앞서 말씀드린 것처럼, 반도체 생산 데이터는 생산 제품(특정 Wafer 혹은 특정 Lot 제품)에 센서 데이터가 종속되는 형태로 기록되는데, 센서 데이터와 공정 데이터를 분리하여 관리하는 것이 마크베이스에는 더 나은 성능을 갖기 때문에 다음과 같은 형태로 변환해야 합니다.
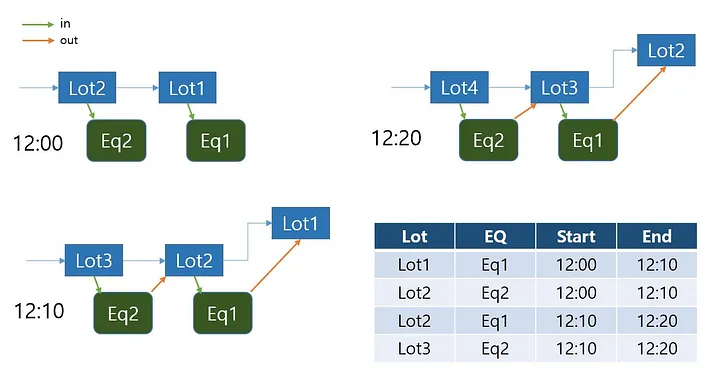
위 그림에서, 생산되는 Lot 단위로 각 장비에 가공을 위해서 들어가고 나가는 시간과 그 Lot 번호를 기록해 둡니다. 이 Lot — eq — start — end 를 기록하는 테이블을 공정 데이터 테이블(PROCESS_DATA)이라고 정의합니다.
각 센서는 각 장비에 설치되어 있으므로, 각 센서 tag id는 생산장비에 따라서 검색이 가능합니다. 센서 tag의 메타데이터로 볼 수 있습니다. 이를 E-R diagram으로 나타내면 아래와 같습니다.

공장-라인-장비-모듈-센서 tag 형태의 ER diagram입니다. 특별한 설명이 필요하지 않을 것이라 생각됩니다.
데이터 검색
이제 센서 tag ID를 장비 단위로 검색할 수 있는 메타데이터와 생산품에 대한 공정 데이터를 가지고 있으므로 원하는 결과는 세 개의 테이블을 join 하여 검색할 수 있습니다.

마크베이스에서 tag 갯수 100만 개, 총 데이터 수 100억 건에 대해서 특정 장비와 특정 lot 기준 검색시 총 검색 데이터 90만 건을 검색한 결과 0.1초 미만의 검색 성능을 나타내었으며 (4core 32G ssd 장비 기준) 총 데이터의 수를 증가시켜도 일정한 성능이 나오는 것을 확인하였습니다.
결론
반도체 생산 데이터를 처리하기 위해서 기존에 사용하던 Hadoop, RDBMS의 한계와 시계열 DBMS의 해결 방안에 대해서 살펴보았습니다. 마크베이스 시계열 DBMS는 반도체 생산 데이터 처리시에도 기존 데이터 처리 시스템의 한계를 벗어난 초고속의 데이터 입력, 검색, 분석 성능을 갖고 있으며, 마크베이스를 적용할 경우에 필요한 데이터 처리 방법 및 검색 방법에 대해서도 살펴보았습니다.
반도체 생산 분야뿐만 아니라, 다른 산업 영역에서도 마크베이스 적용 시에 필요한 기술적 내용이나 추가 진행 사항이 있으면 이후에도 다른 포스트로 찾아뵙겠습니다.
감사합니다.
마크베이스 CTO 심광훈



